
Our website got nay-nayed
One of our brands recently suffered a DDoS attack - thankfully not a sustained one, but enough to impact website availability and rethink our defensive strategies.
What’s a DDoS attack? #
DDoS stands for Distributed Denial of Service. From my besties over at Cloudflare:
A distributed denial-of-service (DDoS) attack is a malicious attempt to disrupt normal traffic of a targeted server, service or network by overwhelming the target or its surrounding infrastructure with a flood of Internet traffic.

So, what did we actually learn from this event?
Log everything #
Absolutely everything. All the logs, all the time.
I had previously set up a centralised log ingestion and analysis system (Graylog) on-prem with a combination of rsyslog and nxlog feeding messages into discrete streams, with extractors to convert the plain text logs into meaningful data.
This was a massive help; we were able to quickly search logs of our reverse-proxy server and our backend Docker instances for messages relating to the incident. We were able to look for a specific timeframe, find the remote IP addresses where the attack originated from, and then search the logs for the rest of our fleet to see if the attacker had been probing anything else.
Unfortunately, the one thing we weren’t logging were nginx access logs. This could have added value to our incident analysis.
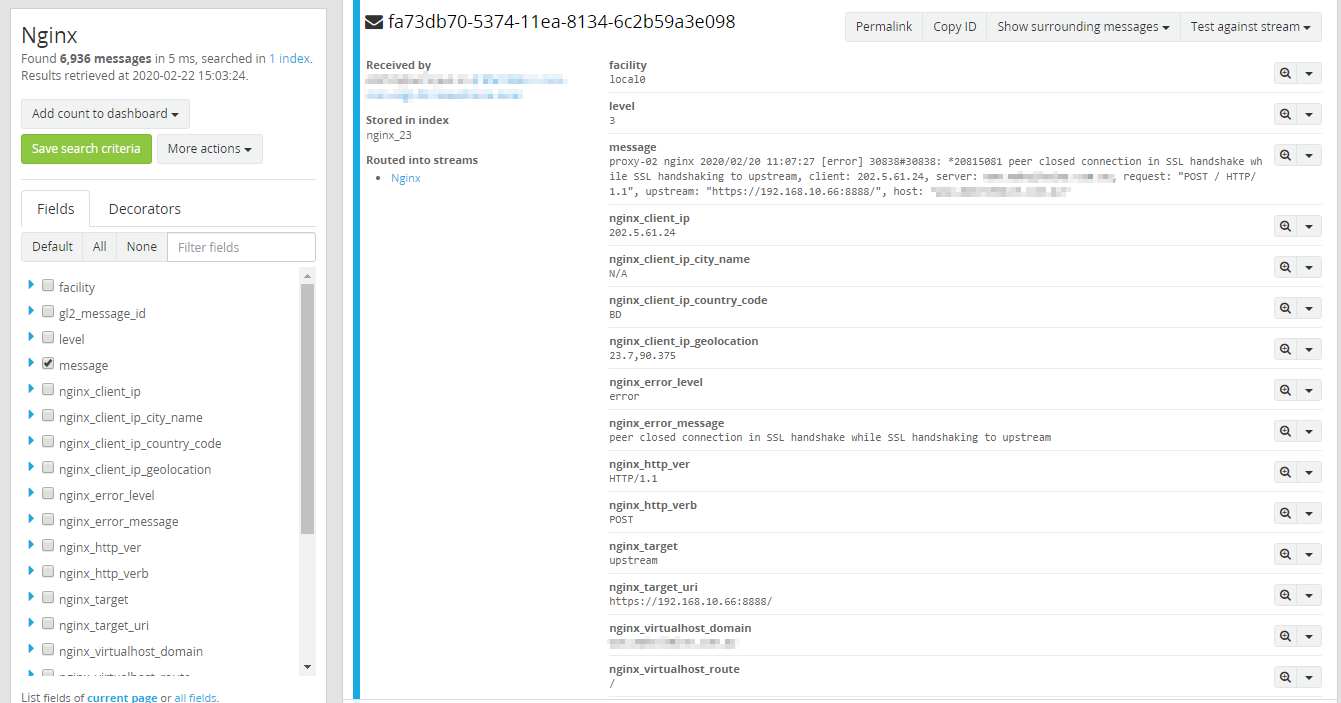
Not all attacks can be stopped by fail2ban #
We had been heavily dependent on fail2ban as our primary mitigation for DDoSing. However, fail2ban works from the logfiles of services it monitors - nginx, sshd, etc.
What happens if the log entries don’t trigger a fail2ban event?
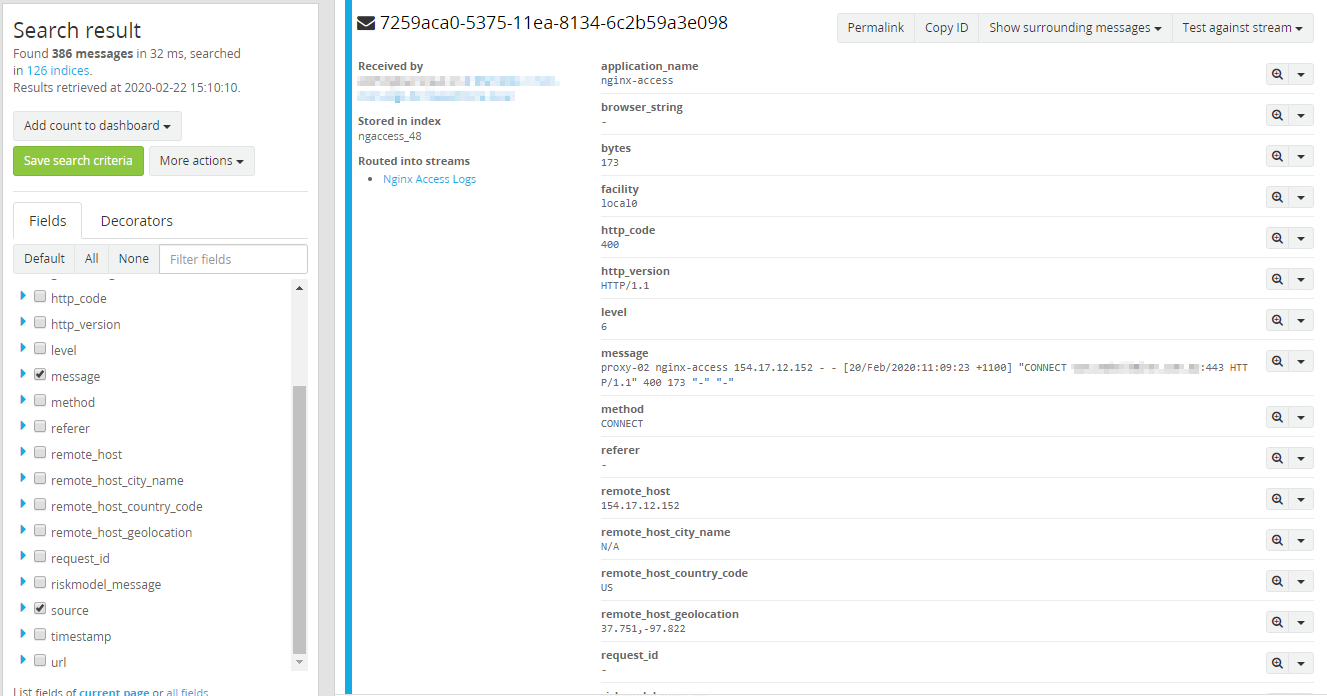
Within less than 60 seconds we had nearly 400 TCP CONNECT events to our reverse proxy from four IP addresses. If we had been using a limiter queue on iptables these connections would have been blocked at the firewall level, massively reducing the risk of a successful DDoS event.
Don’t put all your eggs in one basket #
Due to a myriad of political reasons, this brand’s website was not load balanced and not protected by a WAF. The result was obvious; the backend server crumbled under the load, and our frontend server started throwing HTTP 500 outage pages.
Further, we naivley believed our datacentre would shield us from a DDoS attack. The truth of the matter is, this attack was of such a small scale that it didn’t even register on their alerting, instead showing up as little more than a surge of traffic synonomous with a flash sale/click frenzy. Instead, our website gave way before the DDoS attack fully gained momentum.
Microcache #
The evidence gathered in the course of the investigation suggests that our backend web application gave up the ghost under the load, before our datacentre’s DDoS protection even registered it. That doesn’t bode well for our marketing department. Suppose they organised a click frenzy sale, and our traffic volumes spiked?
One way to mitigate that is to leverage the microcaching functionality of nginx. This little tool lets us cache parts of the website for short periods of time (e.g. 30 seconds), resulting in significant reduction in resource usage on the backend servers.
Now, this would’ve done almost nothing to mitigate the DDoS attack. At best, it would have prolonged it enough for our datacentre’s DDOS protection to get into gear. However, it’s an important real-world demonstration of the capabilities of that brand’s website.
Mitigations #
Well, Cloudflare is an obvious way to mitigate the risk of a DDoS, but you all know my feelings on Cloudflare…
The current plan is to move this brand’s site to AWS, at which point it’ll go behind an auto-scaling group, an application load balancer, and a WAF.
